
 JEXP
JEXP
JEXP
JEXPBisher haben wir im Rahmen dieser Kolumne meist über die Parallelisierung von Operationen auf einer einzigen Maschine und JVM gesprochen. Für viele Anwendungsfälle in Enterprise-Anwendungen ist das auch vollends ausreichend. Wenn nun aber doch grosse Datenmengen jenseits des TeraByte-Bereichs verarbeitet werden müssen, dann ist es schon sinnvoll, sich Lösungen anzuschauen, die die Verarbeitung auf einen Cluster von Maschinen verteilen.
Ich stehe dem BigData Hype etwas skeptisch gegenüberstehe, da meist zuerst geschossen und dann nach dem "Warum" gefragt wird. Dass heisst zuerst einmal wird festgestellt "wir brauchen das", bevor das "wofür" klar ist. Gezielte Verarbeitung von grossen Datenmengen ist dann sinnvoll, wenn dadurch neue und bessere Entscheidungen ermöglicht werden.
Interessanterweise wird die BigData Infrastruktur vor allem von Java-Projekten im Apache Umfeld angetrieben. Natürlich vor allem von Hadoop, Lucene, HBase und Cassandra, Storm, Kafka, aber seit Neuestem auch von Spark, Flink und Ignite.
Heute wollen wir uns Apache Spark mal genauer anschauen, die Anwendungsgebiete betrachten und die APIs und Implementierung vorstellen. An einigen leicht nachvollziehbaren Beispielen soll demonstriert werden, wie statische tabellarische und Graph-Daten verarbeitet werden können, aber auch wie diese Daten als Ereignisstrom innerhalb eines Berechnungsfensters aggregiert werden können.
In Apache Hadoop [Hadoop] wird der Map-Reduce Ansatz umgesetzt, der von Google 2002 TODO [MapReducePaper] veröffentlicht wurde. Dabei wird in 2 Operationen eine Menge von Daten parallel von viele Prozessen auf vielen Maschinen verarbeitet. Die Arbeit wird von einer zentralen Steuerung verteilt, Prozesse gestartet und im Fehlerfall Arbeit wiederholt.
Zuerst werden in einem Map-Schritt die Eingabedaten prozessiert und in einen Strom von Schlüssel-Wert Paare umgewandelt. Dann werden in einem Reduce-Schritt die Paare mit gleichem Schlüssel gemeinsam verarbeitet. Es können prinzipiell beliebig viele Map und Reduce-Schritte hintereinander ausgeführt werden.
Programmiert werden die Map- und Reduce-Funktionen in Java oder anderen JVM-Sprachen.
Für das Erstellen von Hadoop-Jobs muss deutlich mehr Code geschrieben werden, als man eigentlich möchte, selbst wenn die eigentlichen Transformations-Operationen der Businesslogik nur wenige Zeilen bedürfen.
Daher gibt es, wie in der Hadoop-Ökosystem Darstellung ersichtlich, eine ganze Menge (Pig, Hive, Drill, usw.) von alternativen Ansätzen, DSLs und APIs oder SQL, um diesen Aufwand zu vereinfachen.
TODO bei CodeCentric nachfragen, ggf. gibt es auch bei Sigs-Datacom ein nettes Hadoop Bild im Fundus
Als Datenspeicher wird das verteilte HDFS Dateisystem genutzt, die kolumnare HBase Datenbank, die Analyse-Datenbank Impala oder andere (No)SQL Datenbanken als Quellen und Senken für Informationen.
Hadoop und die damit verbundene Infrastruktur wird bekanntlicherweise für die Batchverarbeitung grosser Datenmengen genutzt. Es gibt ein reichhaltiges Ökosystem mit verschiedenen Distributionen von verschiedenen kommerziellen Anbietern.
In Hadoop ist Map-Reduce meist durch die Leistungsfähigkeit des I/O Subsystems begrenzt, sowohl Lese- als auch Schreiboperationen nach HDFS und HBase sind "teuer".
Hadoop hat viele Vorteile, und ermöglicht Unternehmen aller Größe hohe Datenvolumnia im Batchbetrieb zu verabeiten. Die zwei größten Nachteile sind die hohe Latenz bis die Ergebnsise zur Verfügung stehen und die Leistungsbeeinträchtigung durch die zwangsweise Nutzung von Dateissystem und Datenbanken zur Speicherung von Ein- und Ausgabedaten und Ergebnissen zwischen den Verarbeitungsschritten.
Desweiteren sind vor allem in Cloud-Setups mit Virtualisierung schnelle Festplattezugriffe (bes. Latenz) nicht die Regel oder teuer zu bezahlen.
Heutzutage ist Hauptspeicher reichlich vorhanden, schnell und relativ preiswert. Daher bietet sich an, hochperformante Verarbeitung von Daten direkt mittels optimal lokalisierten Operationen im Hauptspeicher vorzunehmen Zwischenergebnisse werden direkt über breitbandige Verbindungen zwischen Maschinen in räumlicher Nähe im selben Rechenzentrum transferiert. In vielen Fällen ist es sogar schneller, ein Ergebnis für eine Datenteilmenge (Partition) neu zu berechnen, als sie von Festplatte zu laden. Festplattenzugriff wird soweit wie möglich vermieden, selbst die Ergebnisse der Transformationen stehen vor allem im Hauptspeicher weiterhin bereit um sie dann interaktiv und performant abzufragen.
Einige Projekte, besonders im Apache Umfeld nutzen einen solchen Ansatz: Spark, Flink und Ignite. Heute wollen wir uns Apache Spark, eine quelloffene, Hadoop-kompatible Datenverarbeitungsplattform, näher anschauen.
Spark entstammt der Feder des AMPLabs (Algorithms, Machine People) des University Berkely als Teil von BDAS (Berkeley Data Analytics Stack).
Heute ist Spark ein Hauptprojekt der Apache Software Foundation, während die Gründer mit Databricks eine Firma zur Vermarktung und Weiterentwicklung einer Rechenzentrums (Cloud) Lösung für Spark gestarted haben. In der Industrie gibt es breite Unterstützung für Spark, die großen Hadoop-Distributoren und -anwender sind schnell auf den neuen Zug aufgesprungen und integrierten es in ihre Big-Data Plattformen.
Spark vereint 3 wichtige Anwendungsgebiete in einem System - Batchverarbeitung, Streaming und interaktive Nutzung bzw. Abfragen.
Mit Spark kommt man sehr schnell zu den ersten Ergebnissen, die Online-Anleitungen sind verständlich geschrieben und enthalten direkt ausführbaren Beispielcode in Scala, Java und Python.
Mittels der Spark-Shell, die eine modifizierte Scala-REPL darstellt, welche schon einen lokalen, minimalen Spark-Cluster hochgefahren hat, können Operationen interaktiv ausgeführt werden.
Hier ein einfaches Beispiel, Worte in einer Datei zählen, das "HelloWorld" von verteilten Datenplattformen.
Dabei wird eine Textdatei eingelesen, auf jede der Zeilen ein Split an Leerzeichen vorgenommen und die Anzahl der Worte pro Zeile aggregiert.
val file = sc.textFile("gutenberg.txt")
val wordsPerLine = file.map( line => line.split(" ").size )
wordsPerLine.reduce( (a,b) => a+b )Die Operationen, die man interaktiv mit der Shell ausführt, würden in einer echten Spark-Anwendung so aussehen:
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
object WordCountApp {
def main(args: Array[String]) {
val fileName = "gutenberg.txt"
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
val file = sc.textFile(fileName)
val wordsPerLine = file.map( line => line.split(" ").size )
val wordsPerFile = wordsPerLine.reduce( (a,b) => a+b )
println("Words in file %s: %d.".format(fileName, wordsPerFile))
}
}Der Hauptunterschied ist, dass der SparkContext selbst erzeugt wird und nicht wie in der Shell zur Verfügung steht.
Mittels sbt kann man die Spark-Anwendung als Scala Projekt aufsetzen.
name := "WordCount" version := "1.0" scalaVersion := "2.10.4" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.3.1"
Nachdem man die Anwendung mit all ihren eigenen Abhängigkeiten mit sbt package zu einem Jar zusammengepackt hat, wird sie mittels spark-submit an den lokalen Spark-Cluster zur Ausführung übergeben.
bin/spark-submit \ --class "WordCountApp" --master local[4] \ target/scala-2.10/wordcount_2.10-1.0.jar
Spark integriert sich sehr gut mit Hadoop, es stellt eine kompatible Ausführungsumgebung dar.
Der Hauptvorteil von Spark liegt in seiner viel effizienteren Map-Reduce Implementierung, die ich hier auch im Detail diskutieren möchte.
In Spark wird Datenverarbeitung mit Hilfe einer kompakten Scala, Python oder Java DSL/API notiert, die Operationen auf den Kerndatenstrukturen von Spark, den Resilient Distributed Datasets (RDD) darstellen.
Die Kernidee von Spark ist so einfach wie sinnvoll. Operationen werden auf einer Datenstruktur abgebildet, die auf Parallelisierung, Partitionen aufbaut Fehlertoleranz. Es sind "resilient distributed datasets" (RDD) also "ausdauernde, verteilte Daten". Sie stellen einen unveränderlichen Datencontainer dar, auf dem übliche Transformationen wie map, filter, sort, group-by, distinct usw. möglich sind, die neue RDDs erzeugen. Mit Aktionen wie reduce, collect, count und foreach werden stattdessen skalare Werte berechnet, oder normale Collections wie Arrays oder Maps eerzeugt, oder Funktionen auf dem RDD ausgeführt. Anders als bei anderen APIs erfolgt die Anwendung von Transformationen nicht sofort, sondern zeitverzögert, nur wenn sie benötigt werden.
Die Operationen auf RDDs werden automatisch über entsprechend viele Datenpartitionen auf den Worker-Instanzen des Spark-Clusters (s.u.) verteilt ausgeführt. Partitionen kann man beim Erzeugen von RDDs angeben, aber es ist auch möglich, diese mittels Transformationen zu ändern, für manche Operationen macht Spark das auch selbstständig im Hintergrund.
Der SparkContext wird am Anfang eines Jobs mit einer Konfiguration erzeugt und stellt dann die wichtigsten Funktionen zur Erzeugung von RDDs bereit.
Er ist auch zuständig für die Verbindung zum Cluster und die Verteilung der Tasks der Jobs auf dem Cluster (s.u) Wenn erst einmal RDDs aus Rohdaten und Datenströmen erzeugt wurden, werden weitere Transformationen direkt auf den RDDs ausgeführt. Dieser Ansatz mittels einer "Fluent-DSL" bietet sich an, um den gewünschten Datenfluss zu beschreiben.
Dabei wird durch diese Transformationen noch keine Ausführung angestossen, sie stellen lediglich die Beschreibung und Verkettung der Operationen dar.
Aus jeder Transformation entsteht ein neues RDD das die Parititionen, Operation mit Parametern und Ergebnismapping enthält. Erst wenn die Ergebnisdaten der Transformationskette irgendwo gebraucht / benutzt werden, wird die Gesamtoperation materialisiert, indem sie aufgeteilt in Aufgaben (Tasks) auf dem Cluster entsprechend geplant und ausgeführt wird.
Dieser DSL Ansatz erlaubt auch eine Menge von Optimierungen, von der Generierung von JVM Bytecode für nicht JVM-Sprachen wie Python und R über Selektives Laden von Daten nach ihrer Nutzung (z.b. nur einige Spalten einer Zeile) bis zur Weiterleitung von Filter-Prädikaten zur Datenquelle, die diese ggf. effizienter umsetzen kann. Diese Ansätze werden auch bei Spark-SQL genutzt.
Zwischenergebnisse können zwar in Variablen gehalten werden, aber nur der Aufruf von rdd.persist() oder rdd.cache() stellt wirklich sicher, dass die Ergebnisse zwischengespeichert werden.
Der Speicherort (Heap, Off-Heap, Serialisiert, Festplatte, Tachyon-RAM Store) kann dabei angegeben werden.
Beim Verlust eines Workers wird die Arbeit vom Master auf die anderen (oder neuen) Worker verteilt.
Da jedes RDD ja die Beschreibung enthält, wie seine Daten aus den vorhandenen Partitionen berechnet werden, wäre das schnell getan, muss aber nicht, wenn diese nicht gerade aktiv angefragt werden. Erst wenn auf das RDD wieder zugegriffen wird, muss die Berechnung wieder angestossen werden.
Die Erzeugung von RDDs erfolgt mittels Funktionen des SparkContexts aus Dateien (lokales Dateisystem, Amazon S3, HDFS), Hadoop-Job-Ergebnissen oder Integrationen mit anderen Datenquellen (z.B. Cassandra).
Auch existierende Datencontainer können mit context.parallelize(collection) in ein RDD gewandelt werden.
Transformationen sind Operationen auf RRDs die die referenzierte Datenpartition verarbeiten und ein neues RDD erzeugen. Dabei wird die Transformation nicht direkt angewandt, sondern nur vorgesehen (lazy evaluation) und erst bei Bedarf ausgeführt.
Beispiele für Transformationen sind im Folgenden aufgeführt:
map(f) |
Wendet eine Funktion auf jeden Wert des RDD an, neues RDD hat Typ des Rückgabewertes der Funktion |
mapPartitions[WithIndex]() |
Wie map() aber jeweils auf einer kompletten Datenpartition |
filter(p) |
Filtert das RDD mittels des Prädikats p |
groupByKey |
Transformiert Tupel in Aggregationen aller Werte pro Schlüssel |
sortByKey |
Sortierung von Tuples |
repartition(n) |
Repartitioniert das RDD auf eine neue Partitionsanzahl n, dies ist eine datentransferlastige Transformation |
… |
… |
Aktionen sind Operationen auf dem RDD, die Daten aggregieren oder anderweitig auf skalare oder Collection-Ergebnisse projizieren, die dann nicht direkt weiter transformiert werden können.
Es sei denn man wandelt sie mittels sc.parallelize(coll) wieder in ein RDD um.
Aktionen beispielsweise Operationen wie:
reduce(f) |
Aggregiert fortlaufend aus Werten ein skalares Ergebnis |
collect() |
Gibt eine Array Repräsentation des RDD zurück, sollte vorher gefiltert werden |
count() |
Anzahl der Elemente im RDD |
saveAsTextFile(file) |
Speichert pro Zeile die |
foreach(f) |
führt Funktion f auf jedem Element aus |
… |
… |
Die Ergebnisse von Operationen können entweder direkt parallel von RDDs oder mittels Aktionen auf dem SparkContext in Dateien oder Datenbanken geschrieben werden.
Meist ist das aber nicht notwendig, da die Ergebnisse einer Anwendung jederzeit in Echtzeit aus der Hauptspeicherrepräsentation abgefragt bzw. bereitgestellt werden können.
Ein Beispiel für eine integrierte Datenvisualisierung von Spark-Ergebnissen ist [Apache Zeppelin].
Spark kann sowohl auf existierenden Hadoop-Cluster-Infrastrukturen laufen, als auch selbst das Cluster-Management übernehmen.
Für Entwicklung und Test kann auch lokal auf der eigenen Maschine ein Setup gestartet werden, in dem der Parallisierungsgrad über die Anzahl der Threads kontrolliert wird.
Anders als in anderen Architekturen ist in Spark das Cluster-Management von der Ausführungssteuerung getrennt, daher kann Spark auch auf existierenden Cluster-Managern (Hadoop-YARN, Apache Mesos) laufen, es bringt aber auch einen eigenen (Standalone) Cluster-Manager mit, den man auch einfach auf der EC2-Infrastruktur deployen kann. Alles was es benötigt ist die Möglichkeit Ausführungsprozesse (Executors) auf dem Cluster zu erzeugen.
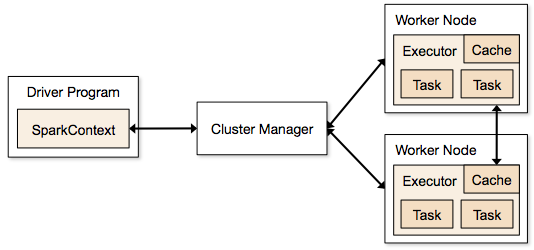
Dieses Prozessmanagement und die Partitionierung der Arbeit obliegt dem SparkContext(Driver), der pro "Anwendung" existiert. Anwendungen sind voneinander isoliert, sie laufen in verschiedenen JVMs und können nur über externen Speicher miteinander kommunizieren. Aktionen auf RDDs werden als Jobs in Spark repräsentiert und über die notwendigen Datenpartitionen und über die einzelnen (voneinander abhängigen) Ausführungsschritte in Aufgaben (Tasks) aufgeteilt die dann entsprechend auf den Prozessen koordiniert platziert werden.
Anwendungen werden als JARs mit Abhängigkeiten (fat-jar) mittels spark-submit an den Cluster übergeben (submitted) und dann auf der Driver-Maschine gestartet von wo aus der Spark-Context die weitere Verteilung übernimmt.
Diese Verteilung kann noch individuell je nach Anforderungen konfiguriert und gesteuert werden.
Netterweise bringt Spark sein eigenens Monitoring mit, dessen Weboberfläche auf der Driver-Maschine auf Port 4040 erreichbar ist:
Spark-SQL, das kompatibel mit Hive ist, macht den Einsatz für all diejenigen einfacher, die viel vertrauter mit SQL als mit Java, Scala oder Python sind. Daher können auch DBAs Spark leichter nutzen als andere Frameworks. Spark-SQL kann auch mit HBase und mittels JDBC und ODBC mit existierenden relationalen Datenbanken und anderen Quellen / Senken kommunizieren.
Im Februar wurden Spark DataFrames vorgestellt, eine wichtige Erweiterung der Plattform. Wie schon vorher in Python und R sind DataFrames Repräsentationen von Tabellen, d.h. eine Gruppe von Spalten mit Werten. DataFrames können aus einer Vielzahl von Quellen erzeugt werden, aus RDDs, relationalen Datenbanken oder Hive, CSV oder JSON Dateien uvm.
Auf diesen können wie gehabt Transformationen und Aktionen ausgeführt werden, dabei stehen auch die DataFrame-Operationen von Python (Pandas) und R zur Verfügung. Auf DataFrames kann auch mittels eines temporären Schemas Spark-SQL direkt ausgeführt werden. Eine sehr nützliche Eigenschaft ist der Join über mehrere Datenquellen, so können Daten aus einer relationalen DB mit JSON aus HDFS verknüpft werden und dann die Ergebnisse aggregiert und projiziert.
# people.json
{"name":"Michael","age":40,"bio":"Michael is father and husband."}
{"name":"Rana","age":9,"bio":"Rana is a smart and friendly girl."}
{"name":"Selma","age":7,"bio":"Selma is a clever and wild monkey."}
val people = sqlContext.load("people.json", "json")
// todo
val young = people.filter(_.age < 21)
# Increment everybody’s age by 1
young.select(young.name, young.age + 1)
# Count the number of young users by gender
young.groupBy("gender").count()
# Join young users with another DataFrame called logs
young.join(logs, logs.userId == users.userId, "left_outer")
You can also incorporate SQL while working with DataFrames, using Spark SQL. This example counts the number of users in the young DataFrame.
young.registerTempTable("young")
context.sql("SELECT count(*) FROM young")
df = context.load("/path/to/people.json")
# RDD-style methods such as map, flatMap are available on DataFrames
# Split the bio text into multiple words.
words = df.select("bio").flatMap(lambda row: row.bio.split(" "))
# Create a new DataFrame to count the number of words
words_df = words.map(lambda w: Row(word=w, cnt=1)).toDF()
word_counts = words_df.groupBy("word").sum()
Der spannende Aspekt an DataFrames ist, dass sie vor der Ausführung massiv optimiert werden können, da mehr über die Struktur bekannt ist. So können Operationen und Prädikate schon zur Datenquelle (z.B. Datenbank oder JSON-Loader) geschickt werden, so dass die Filterung, Selektion oder Voraggregation schon dort erfolgen kann.
Desweiteren werden vom "Catalyst"-Optimierer Ausdrücke voroptimiert und dann für die gesamten DataFrame-Operationen JVM-Bytecode erzeugt. Damit erhält man mit Python, R und Scala (die dann nur als eine Art DSL betrachtet werden) die gleiche hohe Leistung wie für handoptimierten Java-Code.
Immer mehr Entscheidungen basieren nicht mehr nur auf der Aggregation, Selektion und Projektion tabellarischer Daten, sondern auf der Auswertung der vielfältigen Beziehungen von Entitäten zueinander. Anwendungsfälle wie Routing, Matchmaking, Empfehlungsberechnung und Netzwerk- und Sensormanagement benötigen die Repräsentation von Informationen als Netzwerk auf dem Berechnungen ausgeführt werden müssen.
In der Vergangenheit habe ich mit Neo4j eine Echtzeit-Graphdatenbank vorgestellt, die besonders im OLTP Umfeld Anfragen sehr schnell beantworten kann, die entlang der Verbindungen meiner Domänenobjekte navigieren, um nützliche Informationen zu ermitteln.
Obwohl Datenbanken wie Neo4j auch globale Berechnungen auf dem Graph annehmbarer Zeit vornehmen können, sind bestimmte Algorithmen ab einer bestimmten Größe (mehr als 1Mrd Beziehungen) auf einer parallelisierten Infrastruktur effizienter und schneller auszuführen.
Hier kommen Ansätze wie Giraph (Hadoop), GraphLab (Dato) und GraphX ins Spiel. Sie stellen eine Graph-Abstraktion auf einer verteilten Architektur bereit.
GraphX ist der Ansatz von Spark, der sowohl Graph-Strukturen wie Knoten (Vertex) und Kanten (Edge) als auch Operationen darauf zur Verfügung stellt. Speichertechnisch werden sie klassisch auf zwei Tabellen abgebildet, einer Knoten-Tabelle (Id + Attribute), und einer Kanten-Tabelle (Start-Id, End-Id, Attribute).
Die Algorithmen auf dem Graph werden nach dem PregelPrinzip von Google ausgeführt, von Knoten werden Nachrichten mit Werten an ihre Nachbarn geschickt, die diese dann mit ihrem internen Zustand integrieren und neue Nachrichten aussenden.
Hier ist ein Beispiel in Spark für die Implementierung des Page-Rank Algorithmus der prinzipiell aussagt, dass der Rang eines Knoten sich aus der Summe der Ränge der darauf weisenden Nachbarn (Rang durch die Anzahl ihrer ausgehenden Verbindungen) ermittelt. Mit jeder Iteration des Algorithmus wird diese Berechnung erneut durchgeführt, bis eine Stabilisierung eintritt, meist in 5-20 Iterationen.
// Laden der Kantenliste
val graph = GraphLoader.edgeListFile(“hdfs://web.txt”)
// Ermittlung der Kardinalitäten als Initial-Rang
val prGraph = graph.joinVertices(graph.outDegrees)
// Page-Rank, Initialisierung und 3 Funktionen zur
// Nachrichtenverarbeitung und -aggregation und Ermittlung des neuen Inhalts
val pageRank = prGraph.pregel(initialMessage = 0.0, iter = 10)
((oldV, msgSum) => 0.15 + 0.85 * msgSum,
triplet => triplet.src.pr / triplet.src.deg,
(msgA, msgB) => msgA + msgB)
// Top 20 Sortiert nach Rang
pageRank.vertices.top(20) (Ordering.by(_._2)).foreach(println)In Sparks GraphX wurden zur Beschleunigung der Berechnung von Graph-Funktionen eine Menge von Optimierungen in der Infrastruktur integriert. Sowohl die Partitionierung des Graphs zur parallelen Berechnung, Caching von Zwischenergebnissen und Limitierung der Hauptspeichernutzung nur für die auch wirklich genutzten Attribute helfen dabei. Es werden auch speziellere Optimierungen genutzt, z.b. die Analyse des Algorithmus-Codes, um nicht benötigte Standardoperationen die sonst ausgeführt würden wegzulassen. Oder die Nutzung effizienter Speicherstrukturen wie Bitmaps oder spezieller Hash-Indizes.
Damit konnten laut der Veröffentlichung [PageRankGraphX] z.B. die Berechnung von PageRank mit 20 Iterationen auf einem Twitter Datenset mit 1.4Mrd Kanten in 570 Sekunden vorgenommen werden. Die Berechnung erfolgte auf einem Cluster von 16 Maschinen mit jeweils 8 Kernen und 68 GB RAM.
Wie immer gibt es natürlich viel mehr zu berichten, als Platz in einer Kolumne zur Verfügung steht. Da wäre zum einen die Machine-Learning Bibliothek von Spark (MLlib), zum anderen die Integration mit den verschiedenen Hadoop-Distributionen und die Anwendung von Spark im größeren Kontext mit mehr praktischen Beispielen. Ich hoffe, die Referenzen im Anhang sind ein guter Ausgangspunkt für die weitere Arbeit mit Spark.
Ich plane auch in einer weiteren Kolumne mal weiter hinter die Kulissen von Spark und Apache Flink zu schauen und die beiden Frameworks miteinander zu vergleichen.
Wie immer würde ich mich über Feedback freuen, einfach per Tweet oder E-Mail.
[MapReducePaper] http://research.google.com/archive/mapreduce.html
[Apache Spark] https://spark.apache.org/
[SortingBenchmark]https://databricks.com/blog/2014/10/10/spark-petabyte-sort.html
[SparkEcosystem] http://emerginginsightsnow.com/2015/05/17/apache-spark-ecosystem-grows-rapidly-has-hadoop-met-its-match/
[DZone Refcard Spark] http://refcardz.dzone.com/refcardz/apache-spark
[SparkSlides]http://slideshare.net/databricks/databricks-primer-spark
[Spark Ökosystem]http://emerginginsightsnow.com/2015/05/17/apache-spark-ecosystem-grows-rapidly-has-hadoop-met-its-match/
[Apache Flink] http://data-artisans.com/apache-flink-new-kid-on-the-block.html
[GraphXPaper] https://amplab.cs.berkeley.edu/wp-content/uploads/2014/02/graphx.pdf
[Zeppelin Data Visualization for Spark] https://zeppelin.incubator.apache.org/