
 JEXP
JEXP
JEXP
JEXP|
Note
|
Final für Frau Weinert |
Wenn wir bisher auf Java’s Speicher geschaut haben, dann ist das meist im Rahmen von Speichermanagement, d.h. Erzeugung (Allocation) und Beseitigung (Garbage Collection) von Objekten geschehen. Die Nutzung des Heaps mit den verschiedenen Generationen (Young-, Old- und Perm-Gen) sowie die verschiedenen Garbage-Collectors, sollen in dieser Kolumne aber nicht im Mittelpunkt stehen, sondern das Speichermodell das der Java Virtual Machine (JVM) zugrundeliegt.
Nachdem wir vor kurzem schon einmal Aleksey Shipilev’s Arbeit, den Java Measurement Harness (JMH) im Visier hatten, will ich ihn auch dieses Mal zu einem anderen, spannenden aber auch komplizierten Teil der JVM-Spezifikation zitieren, dem Java Speichermodell (JMM). Er hat dazu einen ausführlichen Beitrag geschrieben, der einen eine Weile beschäftigen kann.
Jeder hat seine ganz eigenen Erfahrungen mit Concurrency, Race-Conditions und der Sichtbarkeit von Änderungen für andere Threads gehabt und es gibt da sicher so einige Gruselgeschichten zu berichten. Diese Art von Fehlern ist schwer zu finden und deterministisch zu reproduzieren, meistens hat man sich einige Informationen angelesen und hergeleitet, aber oft ist das eher gefährliches Halbwissen.
Aleksey geht seinem sehr langen Artikel [Shipilev JMM] ausführlich auf viele Details der Java Language Specification (JLS) bezüglich des Speichermodells ein, von denen ich im folgenden einige erörtern möchte.
Generell ist die Frage, die für die verschiedensten Kontexte, Zustände und Situationen beantwortet werden muss: "Welchen Wert siehts eine bestimmte Leseoperation". Das ganze ist natürlich nur für nebenläufige Programme wirklich interessant, bei sequentiellem Ablauf ist die Antwort deterministisch. Dort ist nur die Abfolge von Speicher-Lese und Schreiboperationen für Sprachkonstrukte relevant, d.h. wann lesen und/oder schreiben welche Operationen welche Werte und wie werden sie nacheinander ausgeführt (auch abhängig von Präzendenz und Compiler-Optimierungen).
Eine Sprachspezifikation wie die der JVM besteht aus dem einfachen Teil, der die Syntax der Sprache festlegt und beschreibt, und der weitaus komplexeren Beschreibung des Laufzeitverhaltens.
Das Verhalten wird oft im Rahmen einer Abstrakten Maschine dargestellt, deren Operationen und Speichermodell detailliert dargelegt sind.
(Diese Maschine wird dann von Interpretern emuliert oder von Compilern aus dem Quellcode umgesetzt, in beiden Fällen kann es zu Problemen kommen.)
Im Endeffekt handelt es sich bei der Umsetzung von Sprachen, Compiler und Speichermodellen immer um einen Balanceakt. Man will sie so einfach, performant und korrekt wie möglich gestalten und muss dafür jeweils Abstriche an anderen Aspekten hinnehmen.
Wir wollen im Folgenden einige Aspekte im Detail betrachten
In einer Programmiersprache geht man eigentlich davon aus, dass jeder Lese- und Schreibzugriff eines Feldes atomar ist. Leider lässt uns dabei die Hardware im Stich, denn je nach Architektur können längere Werte nicht mehr atomar mit einer Hardwareinstruktion gehandhabt werden. In Java betrifft das auf einigen Plattformen (32-bit) den Zugriff auf Werte vom Typ long und double (jeweils 8 Bytes). Und wenn man mindestens 2 Operationen benötigt, dann ist nicht automatisch sichergestellt, dass diese noch atomar ablaufen, ohne dass sich ein weiterer Zugriff dazwischenschmuggelt. Dasselbe Problem tritt auf, wenn ein Wert auf zwei Zeilen des Prozessor-Caches oder auf Speicherbereiche mit dem falschen Alignment verteilt ist.
Daher sind im Java-Speichermodelle nur atomare Speicheroperationen bis zu 32 Bit Länge garantiert (Kompatibilität zu 32-Bit-Prozessoren), bei längeren Werten muss mit volatile oder final Modifikatoren eine atomare Operation erzwungen werden (wenn nötig).
Dann treffen der Compiler und die JVM spezielle, aufwändigere Vorkehrungen dass diese Operationen auch atomar ausgeführt werden und z.b. Speicher- und Cachezellen zwangsweise publiziert werden.
Das ist auch der Grund warum Objektreferenzen in Java maximal 32 Bit lang sind, damit sie garantiert atomar gelesen und geschrieben werden können.
Da diese Operationen deutlich teurer sind, werden sie nicht standardmässig genutzt und es liegt in der Verantwortung des Anwenders, bei Notwendigkeit (z.b. parallelem Zugriff) die Variablen entsprechend geschützt zu deklarieren.
Wenn es für die Wertlänge keine atomaren Prozessoroperationen gibt, muss man sich anders behelfen, entweder über Compare and Swap (CAS) Prozessoroperationen oder sogar Sperren (Locks) auf dem Maschinenlevel.
Zum Beispiel in AtomicLong werden atomare Lese- oder Schreiboperationen erreicht, indem der gekapselte Wert als volatiles Feld deklariert ist. Komplexere Operationen wie Erhöhen um einen Wert (wofür man ihn Lesen und Schreiben muss) werden über CAS umgesetzt.
Für die Aktualisierung von Feldwerten kann es abhängig von der Lesebreite der Hardware notwendig sein, mehrere Feldelemente auf einmal zu lesen, den Wert zu ändern und den ganzen Block auf einmal wieder zurückzuschreiben. Man kann sich leicht vorstellen, dass das bei konkurrierendem Zugriff schnell danebengeht, so dass ein Thread Änderungen eines parallel laufenden zweiten Threads überschreibt.
Da die meisten Maschinen eine Mindestbreite des Zugriffes von einem Byte haben, können z.B. Boolean-Felder nicht pauschal als Bitsets abgebildet werden. In der Java Spezifikation sind Datenstrukturen mit einer Breite kleiner als ein Byte verboten, um das generell auszuschliessen. Wichtig ist dies auch bei Optimierungen durch Programmierer oder Compiler, die nebenläufig größere Puffer auf einmal lesen, bearbeiten und zurückschreiben. Diese Zugriffe müssen durch entsprechende Synchronisationsmechanismen geschützt werden.
Parallele Operationen in einem Programm können auf diesselben Register und Speicherzellen lesend und schreibend zugreifen. Die Reihenfolge des Ablaufs bestimmt in der Theorie welche Werte diese Threads sehen. In Realität sieht das noch etwas anders aus. Ohne weitere Hinweise, ist der Compiler in der Lage diverse Operationen umzusortieren, um Abläufe effizienter zu gestalten.
Auch im Prozessor ist eine aggressive Optimierung der Reihenfolge und optmistische Spekulationen über Speicherzugriffe und Operationen an der Tagesordnung (Im Fehlerfall wird die Spekulation dann verworfen und ggf. die aktuelle Pipeline zurückgesetzt). Ausserdem sind Prozessoren heutzutage mit einem schnellen, mehrstufigen (meist 3) Cachesystem ausgestattet, das lokale Änderungen an Werten erlaubt, ohne dass diese sofort in den Speicher zurückgeschrieben oder anderen beteiligten Prozessorkernen bekannt gemacht müssen.
Aus diesen zwei Gründen können Schreiboperationen eines Threads für andere Threads komplett unsichtbar sein und damit zur falschen Aussagen beim Lesen von Werten führen, die dann im weiteren Verlauf die Korrektheit des Programms beeinflussen.
Für die meisten Operationen im Programm sind diese Optimierungen auch wichtig und unproblematisch, da sie im lokalen Kontext eines Threads erfolgen, und damit massive Leistungssteigerungen hervorrufen können. Für das aktive Bekanntmachen von Änderungen und Verhindern solcher Optimierungen gibt es das Konzept der Speicherbarrieren (memory barriers). D.h. Instruktionen die dem Prozessor mitteilen das Speicheroperationen in einer festen Reihenfolge und mit globaler Sichtbarkeit erfolgen müssen.
Der von Aleksey dargestellte Ansatz zur Beschreibung der Herstellung einer konsistenten Ausführungsreihenfolge von Operationen wird von ihm als "Sequential Consistency - Data Race Free (SC-DRF)" bezeichnet. Dabei wird aus einer Reihe von Operationsabhängigkeiten für verschiedene Teilaspekte (Abfolge, Synchronisation, Umordnungsrestriktionen) die Menge der möglichen Abfolgen von Instruktionen immer weiter reduziert, bis die konsistenten Sequenzen übrig bleiben.
Um ein Speichermodell sinnvoll so auf Hardware abzubilden, dass die Konsistenz der Operationen noch gewährleistet ist (trotz extremer Optimierungen von Compiler und Prozessor), muss es Festlegungen geben welche Operationen wie voneinander abhängig sind (oder nicht) und welche Ausführungsreihenfolge garantiert sein muss. Also Regeln, welche Operationen (besonders Feld und Monitor-Operationen) warum nicht umsortiert werden dürfen.
Nur so kann man Race-Conditions, d.h. abhängige Werte werden gelesen bevor sie geschrieben werden, verhindern. Man kann aber nicht die Reihenfolge eines jeden Befehls fixieren, da dass die Möglichkeiten moderner Prozessoren zur Optimierung komplett aushebeln würde und als Ergebnis nur im Schneckentempo ausgeführt würde.
Im Java Memory Model (JMM) werden diese Zusammenhänge über Regeln, die spezielle Aktionen und Reihenfolgen/Abhängigkeiten festlegen, formalisiert.
Der Ablauf eines "abstrakten" Programms wird über einzelne Aktionen definiert, das können je nach Art der Betrachtung entweder alle Instruktionen (Programmaction) sein, oder nur bestimmte Speicherzugriffe (Synchronizationaction).
Da die Instruktionen durch das Scheduling mehrerer Threads und prinzipiell jederzeit in einer beliebigen Reihenfolge ausgeführt werden können, legen Ausführungsordnungen (~order) die möglichen und je nach Art der Betrachtung erlaubten Reihenfolgen von Aktionen fest.
Dass heisst, die Menge aller möglichen Ausführungen ist wie ein Q-Bit und die "Beobachtung" durch die erlaubten Reihenfolgen von Aktionen fixieren bestimmte Aspekte der Möglichkeiten, so dass zum Schluss nur die gültigen (aber meist mehr als eine, durchaus variable) Ausführungen übrigbleiben.
Programmaktionen (Program Action, PA): stellen die ganz normalen Instruktionen/Statements des Programmcodes dar
Synchronsationsaktionen (SynchronizationAction, SA): Nur Speicherzugriffsmechanismen, sowie Start und Ende von Threads, Monitors und Locks sind hier relevant
wie z.b. Lese "1" von "x" als read(x): 1 oder Schreibe "1" auf "x" als write(x,1)
Die einzelnen Aktionen werden dann über gerichtete Verknüpfungen zu konkreten Programm(ausführungen) verbunden.
Program Order (PO),
originale sequentielle Reihenfolge der Programmaktionen (Statements) innerhalb des Programms und eines Threads,
Verbindung zum Originalcode
Aktionen können für eine Ausführung aber umgeordnet werden
Synchronization Order (SO),
nur Synchronizationsaktionen stehen in dieser expliziten Reihenfolge, alle andere Operationen werden nicht betrachtet,
SO legt die bedingte Reihenfolge von Schreib und Leseoperationen fest.
Synchronization With (SW), Sichtbarkeitsreihenfolge von Speicherzugriffen
Happens Before (HB), Kombination der vorangegangenen Regeln, welche Aktionen sind wie voneinander abhängig und welche Sichtbarkeiten aller Speicherzustände gibt es für nachfolgende Leseoperationen
einmal gesehene Werte, fixieren was vorher passiert sein muss, über Speicherstellen hinweg
Mit diesen 4 Ausführungsreihenfolgen, wird die Menge aller möglichen Ausführungspfade von mehreren Programmfragmenten über mehrere Threads annotatiert. Die bei der dazugehörigen Regelanwendung übrig bleibenden, validen Konstruktionen stellen die erlaubten Ausführungsreihenfolgen dar.
Wenn man nur genügend "volatile" Modifikatoren über ein Programm sprenkelt wird es irgendwann entscheidbar (sequentially consistent), da irgendwann genug Programmaktionen in Synchronizationsaktionen umgewandelt wurden, die dann eine ausreichend definierte, globale Reihenfolge fixieren
Im Allgemeinen kann man "Happens Before"-Verbindungen zwischen Aktionen als Paare einer release (Updates veröffentlichen) und aquire (Updates erhalten) betrachten. Dies gilt hier nur für eine Variable, es wird später mittels der "memory barrier" als generelle Publikation erweitert.
Beispiel:
class Test {
volatile Object value;
public synchronized set(Object value) { if (this.value == null) this.value = value; }
public Object get() { return this.value; }
}
Dieses Beispiel funktioniert, da die synchronized Methode am Ende ein release erzeugt und der Zugriff auf die volatile Variable das entsprechende acquire.
Bei Benchmarks zeigen sich die Kosten von "volatilen" Variablen aber auch des Teilens von Zustand/Speicher im Allgemeinen, die notwendigen Zusicherungen für threadübergreifende Sichtbarkeit es verhindern, dass der Compiler Programmoptimierungen vornehmen kann, die sonst massive Auswirkungen hätten.
Wenn alle Ausführungsreihenfolgen angewandt und validiert wurden, bleiben nur die Programmabläufe als gültig zurück, die allen Restriktionen standhalten. Dieser kleine Teil ist dann, was vom Compiler generiert und der JVM ausgeführt werden kann, ohne dass die Invarianten und Vor- und Nachbedingungen verletzt werden.
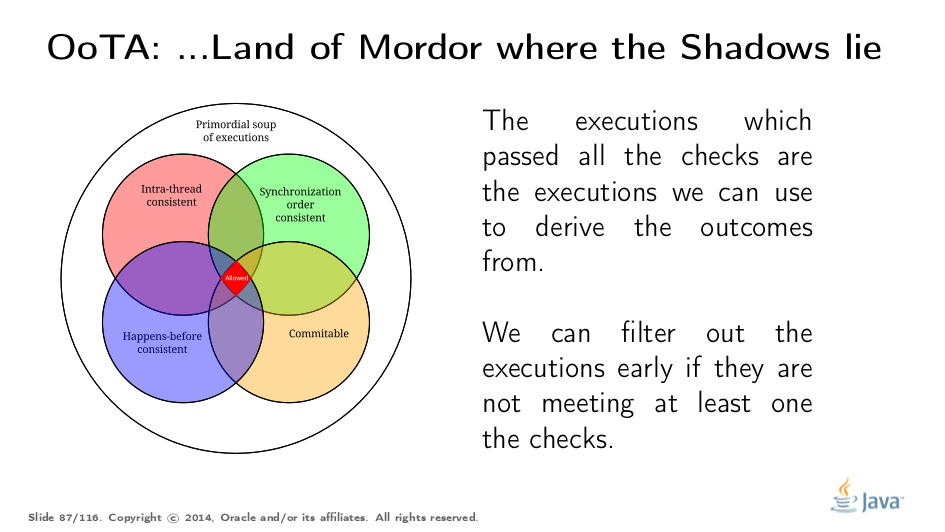
Und die Hilfen, die man als Programmierer gibt, wie volatile, final, synchronized und Threadsteuerung helfen dabei, die validen Lese- und Schreiboperationen auf geteilte Resourcen zu markieren und korrekt abzusichern und zu publizieren.
Das Thema Formalisierung des JMM ist nicht so einfach zu verstehen und auch nicht so einfach zu erklären, wie ich mir vorgestellt habe. Ich hoffe, Sie wurden nicht überfordert. Ich fand das Ganze sehr spannend und einsichtsreich.
(memory barrier, memory fence)
Speicherbarrieren dienen zur Publikation von Änderungen über Prozessorgrenzen hinweg, sie werden zwischen Speicherzugriffen aktiv. Sie stellen sicher, dass bestimmte Aktualisierungen nicht nur im lokalen Prozessorcache widergespiegelt werden, sondern auch für Threads auf anderen Prozessoren sichtbar sind. Dazu werden beim Eintreffen einer solchen Instruktion die Cache-Lines und Schreibpuffer des Prozessors geflushed. Bei Einzelprozessoren ist das nicht notwendig sie teilen sich einen Prozessorcache, nur bei Multiprozessoren.
Interessanterweise müssen sie auch vom Compiler erzeugt werden, wenn der eigentliche Feldzugriff auf das "synchronisierte" Feld wegoptimiert wird, da in ihrem Kontrakt steht, dass sie auch alle vorherigen Speicheroperationen sichtbar machen.
Die teure, grobgranulare "Fence" Operation der meisten Prozessoren stellt sicher, dass alle Schreiboperationen vor der Grenze allen Leseoperationen nach der Grenze zur Verfügung stehen.
Es gibt 4 Arten von Speicherbarrieren, je nachdem welches Paar von Operationen sie trennen. Die am häufigsten vorkommende ist, wie schon zu erwarten StoreLoad, dass neben seiner eigentlichen Operation auch noch das Lesen nachfolgend, durch einen anderen Prozessor gespeicherter, noch nicht publizierter Werte verhindert, so dass diese nicht zufällig den publizierten Wert überdecken.
Compiler müssen Barrieren pessimistisch zwischen entsprechenden Speicherzugriffen eingefügt werden, da eine globale Optimierung der Platzierung nicht trivial möglich ist.
Es ist oft nicht entscheidbar, was für eine Operation einem Lese- oder Schreibzugriff folgt, zum Beispiel wenn dieser von einem return gefolgt wird.
Beispiel:
class A {
int f;
public A() { f = 42; }
}
Thread 1 |
Thread 2 |
A a = new A(); |
if ( a != null) out.println(a.f); |
Welche Ausgaben kann Thread 2 produzieren?
Erwartet:
Nichts
42
Nicht erwartet, kommt aber trotzdem:
0
NullPointerException
Warum? Race-Conditions können machen dass a.f noch nicht initialisiert ist, wenn Thread 2 schon auf darauf zugreift.
Die NullPointer Exception kann aus einem Fall kommen, in dem Thread 2, zwei verschiedene Werte von a sieht, einmal den
initialisierten, so dass die if-Bedingung erfüllt ist, dann aber wieder den nicht-initialisierten, so dass es zur NPE kommt.
Wie kann man das verhindern?
Indem das Feld als final int f; deklariert wird.
Damit wird es nicht nur unveränderlich, sondern was hier viel wichtiger ist, es bekommt einen sauberen Publikationsmechanismus für die Sichtbarkeit seines Wertes.
Der Compiler darf auserdem nicht mehr die Referenz für a anderen Threads zur Verfügung stellen bevor nicht alle finalen Felder gesetzt wurden.
Und damit werden auch alle anderen Änderungen die bis dahin passiert sind, verfügbar.
Damit wird auch effektiv verhindert, dass unsere eigentlich geschützten (immutablen) Objekte (absichtlich) einem anderen Konsumenten vor der fertigen Initialisierung zur Verfügung gestellt werden, ohne dass wir es kontrollieren können.
Die Implementierung von final ist leichter als gedacht.
Mit einer Speicherbarriere (freeze action) am Ende des Konstruktors, Initialisierung der Felder vor Publikation der Instanz, und einer Garantie dass die Referenzen der Instanz und damit auch der finalen Felder erst geladen werden, wenn die Initialisierung abgeschlossen ist.
Durch die Speicherbarriere sind auch Aktualisierungen automatisch publiziert auf die finale Felder referenzieren.
Dieser Publikationsmechanismus funktioniert wirklich gut, es gibt nur eine Ausnahme.
Man muss aufpassen, dass man die aktuelle Instanz der Klasse nicht während der Konstrukturausführung unbeabsichtigt globalen Variablen zuzuweisen. Andere Threads können über diese Variable dann eine unpublizierte Referenz auf die Instanz und ihre finalen Felder zugreifen. Das kann auch passieren, indem während der Konstrukturausführung fremde Methoden mit der eigenen Referenz (this) aufgerufen werden und damit ohne es zu wollen, die noch nicht initialisierte Instanz zu zeitig geteilt wird.
[JLS - Memory Model] http://docs.oracle.com/javase/specs/jls/se8/html/jls-17.html#jls-17.4
[Shipilev JMM Pragmatics] http://shipilev.net/blog/2014/jmm-pragmatics/
[Goetz Value Types] http://cr.openjdk.java.net/~jrose/values/values-0.html
[Rose Struct Tearing] https://blogs.oracle.com/jrose/entry/value_types_and_struct_tearing
[Rose Value Types] https://blogs.oracle.com/jrose/entry/value_types_in_the_vm
[JEP 188 JMM Update] http://openjdk.java.net/jeps/188
[Shipilev Atomic Access] http://shipilev.net/blog/2014/all-accesses-are-atomic/
[Lea JSR 133 Cookbook for Compiler Writers] http://gee.cs.oswego.edu/dl/jmm/cookbook.html (konservative Interpretation des JMM)