I came across this tweet, which sounded really interesting.
@MappingMetaphor: Metaphor Map now complete! Remaining data now up, and showing nearly 12,000 metaphorical connections: http://mappingmetaphor.arts.gla.ac.uk/
Mapping Metaphor
The Metaphor Map of English shows the metaphorical links which have been identified between different areas of meaning. These links can be from the Anglo-Saxon period right up to the present day so the map covers 1300 years of the English language. This allows us the opportunity to track metaphorical ways of thinking and expressing ourselves over more than a millennium; see the Metaphor in English section for more information.
The Metaphor Map was built as part of the Mapping Metaphor with the Historical Thesaurus project. This was completed by a team in English Language at the University of Glasgow and funded by the Arts and Humanities Research Council from 2012 to early 2015. The Metaphor Map is based on the Historical Thesaurus of English, which was published in 2009 by Oxford University Press as the Historical Thesaurus of the Oxford English Dictionary.
The site is really nice and fun to explore, with an interesting data visualization of the metaphoric connections between areas of language and thought:

When most people think of metaphor, they cast their minds back to school and remember examples from poetry and drama, such as Shakespeare’s “Juliet is the sun”. This is unsurprising; metaphor is usually described as a literary phenomenon used to create arresting images in the mind of the reader. However, linguists would argue that metaphor is far more pervasive within our language and indeed within thought itself.
Useful natural language correlation network are always fun to work with, so let’s have a look at it in a graph database.
Install Neo4j & APOC
-
Download and install Neo4j-Desktop from http://neo4j.com/download/other-releases
-
Create a database and add the APOC procedure library.
-
I also installed Neo4j Graph Algorithms to use later.
-
Start the database.
Download Data
|
Note
|
All the data is available from: Mapping Metaphor with the Historical Thesaurus. 2015. Metaphor Map of English Glasgow: University of Glasgow. http://mappingmetaphor.arts.gla.ac.uk. |
-
select "Advanced Search",
-
select all categories (you’re interested in)
-
select "Connections between selected sections and all other sections"
-
Metaphor Strength: "Both"
-
Click "Search"
-
Select "View results as a table"
-
Click the "Download" icon in the left box
The downloaded file "metaphor.csv" should contain almost 12k lines of metaphors:
Copy metaphor.csv into the import folder of your database ("Open Folder") or in an http-accessible location to load via an http-url.
Run Import
Our data model is really simple, we have
-
:Categorynodes withidandname. -
:Strongor:Weakrelationships between them with thestartproperty for the start era andexamplesfor the example words.
A more elaborate model could model the Metaphor as node, with the Words too and Era too and connect them. I was just not sure, what to name the metaphor, that information was missing in the data. But for this demonstration the simpler model is good enough.
For good measure.
create constraint on (c:Category) assert c.id is unique;Run this Cypher statement to import in a few seconds
// load csv as individual lines keyed with header names
LOAD CSV WITH HEADERS FROM "file:///metaphor.csv" AS line
// get-or-create first category (note typo in name header)
merge (c1:Category {id:line.`Category 1 ID`}) ON CREATE SET c1.name=line.`Categroy 1 Name`
// get-or-create second category
merge (c2:Category {id:line.`Category 2 ID`}) ON CREATE SET c2.name=line.`Category 2 Name`
// depending on direction flip order of c1,c2
with line, case line.Direction when '>' then [c1,c2] else [c2,c1] end as cat,
// split words on ';' and remove last empty entry
apoc.coll.toSet(split(line.`Examples of metaphor`,';'))[0..-1] as words
// create relatiosnship with dynamic type, set era & words as relatiosnship properties
call apoc.create.relationship(cat[0],line.Strength,{start:line.`Start Era`, examples:words},cat[1]) yield rel
// return rows processed
return count(*)I rendered the category nodes pretty large so that you can read the names, and have the "Strong" links display their "words" instead.
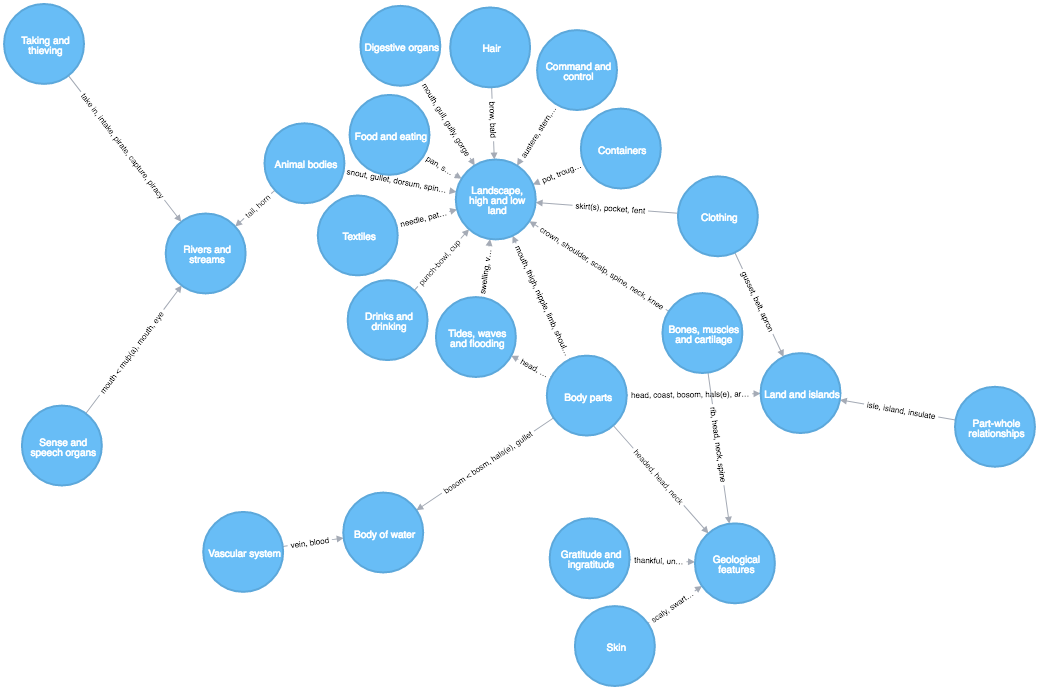
For finding categories quickly
create index on :Category(name);Run graph algorithms.
Degree distribution
╒════════╤═══════════╤═══════╤═════╤═════╤═════╤═════╤═════╤══════╤═════╤═════╤═════════════════╕ │"type" │"direction"│"total"│"p50"│"p75"│"p90"│"p95"│"p99"│"p999"│"max"│"min"│"mean" │ ╞════════╪═══════════╪═══════╪═════╪═════╪═════╪═════╪═════╪══════╪═════╪═════╪═════════════════╡ │"Weak" │"OUTGOING" │7908 │11 │31 │48 │61 │84 │100 │100 │0 │19.10144927536232│ │"Strong"│"OUTGOING" │3974 │3 │12 │28 │37 │86 │107 │107 │0 │9.599033816425122│ └────────┴───────────┴───────┴─────┴─────┴─────┴─────┴─────┴──────┴─────┴─────┴─────────────────┘
Top 10 Categories by in-degree:
MATCH (c:Category) WITH c,size( (c)-->()) as out,size( (c)<--()) as in RETURN c.id, c.name,in, out ORDER BY in DESC LIMIT 10; ╒══════╤═════════════════════════╤════╤═════╕ │"c.id"│"c.name" │"in"│"out"│ ╞══════╪═════════════════════════╪════╪═════╡ │"2D06"│"Emotional suffering" │119 │7 │ ├──────┼─────────────────────────┼────┼─────┤ │"2C02"│"Bad" │119 │7 │ ├──────┼─────────────────────────┼────┼─────┤ │"3M06"│"Literature" │116 │29 │ ├──────┼─────────────────────────┼────┼─────┤ │"1O22"│"Behaviour and conduct" │109 │10 │ ├──────┼─────────────────────────┼────┼─────┤ │"3L02"│"Money" │106 │44 │ ├──────┼─────────────────────────┼────┼─────┤ │"2C01"│"Good" │105 │2 │ ├──────┼─────────────────────────┼────┼─────┤ │"1P28"│"Greatness and intensity"│104 │2 │ ├──────┼─────────────────────────┼────┼─────┤ │"2A22"│"Truth and falsity" │104 │5 │ ├──────┼─────────────────────────┼────┼─────┤ │"2D08"│"Love and friendship" │100 │17 │ ├──────┼─────────────────────────┼────┼─────┤ │"2A18"│"Intelligibility" │99 │5 │ └──────┴─────────────────────────┴────┴─────┘
Outgoing Page-Rank of Categories
call algo.pageRank.stream(null,null) yield node, score with node, toInt(score*10) as score order by score desc limit 10 return node.name, score/10.0 as score; ╒══════════════════════════════════════╤═══════╕ │"node.name" │"score"│ ╞══════════════════════════════════════╪═══════╡ │"Greatness and intensity" │5.6 │ ├──────────────────────────────────────┼───────┤ │"Colour " │3.5 │ ├──────────────────────────────────────┼───────┤ │"Unimportance" │3.5 │ ├──────────────────────────────────────┼───────┤ │"Importance" │3.4 │ ├──────────────────────────────────────┼───────┤ │"Hatred and hostility" │3.4 │ ├──────────────────────────────────────┼───────┤ │"Plants" │2.9 │ ├──────────────────────────────────────┼───────┤ │"Good" │2.9 │ ├──────────────────────────────────────┼───────┤ │"Age" │2.8 │ ├──────────────────────────────────────┼───────┤ │"Love and friendship" │2.7 │ ├──────────────────────────────────────┼───────┤ │"Memory, commemoration and revocation"│2.6 │ └──────────────────────────────────────┴───────┘
Funny that both importance and unimportance have such a high rank.
call algo.pageRank.stream(null,null,{direction:'INCOMNG'}) yield node, score
with node, toInt(score*10) as score order by score desc limit 10
return node.name, score/10.0 as score;
Betweeness Centrality
Which categories connect others:
call algo.betweenness.stream('Category','Strong') yield nodeId, centrality as score
match (node) where id(node) = nodeId
with node, toInt(score) as score order by score desc limit 10
return node.id, node.name, score;
╒═════════╤═══════════════════════════════════════════╤═══════╕
│"node.id"│"node.name" │"score"│
╞═════════╪═══════════════════════════════════════════╪═══════╡
│"2C01" │"Good" │165912 │
├─────────┼───────────────────────────────────────────┼───────┤
│"1E02" │"Animal categories, habitats and behaviour"│131109 │
├─────────┼───────────────────────────────────────────┼───────┤
│"3D05" │"Authority, rebellion and freedom" │108292 │
├─────────┼───────────────────────────────────────────┼───────┤
│"2D06" │"Emotional suffering" │87551 │
├─────────┼───────────────────────────────────────────┼───────┤
│"1J34" │"Colour " │83595 │
├─────────┼───────────────────────────────────────────┼───────┤
│"1E05" │"Insects and other invertebrates" │77171 │
├─────────┼───────────────────────────────────────────┼───────┤
│"3D01" │"Command and control" │71873 │
├─────────┼───────────────────────────────────────────┼───────┤
│"1O20" │"Vigorous action and degrees of violence" │65028 │
├─────────┼───────────────────────────────────────────┼───────┤
│"1C03" │"Mental health" │64567 │
├─────────┼───────────────────────────────────────────┼───────┤
│"1F01" │"Plants" │59444 │
└─────────┴───────────────────────────────────────────┴───────┘
There are many other explorative queries and insights we can draw from this.
Let me know in the comments what you’d be interested in.