Building an Import Tool for Relational to Neo4j over one Weekend
Last Saturday Night around 11pm when the family was fast asleep, I decided to finally write a tool that I had wanted to build for a while…
An automatic importer for relational databases into Neo4j.
I had all the ingredients at hand
-
JDBC for accessing relational databases, and SchemaCrawler for a convenient way of extracting the meta-information. SchemaSpy would have worked as well.
-
Neo4j 2.2 with its massively scalable parallel batch importer API (which is also the foundation for the neo4j-import tool).
This API also takes care of linking of nodes via external id’s (which don’t have to be stored). -
And a bunch of ideas on how to declare rules for deciding what should become a node and what a relationship:
My Transformation Rules:
-
tables become nodes, the primary key becomes the linking-id (doesn’t have to be stored)
-
foreign keys for 1:1, 1:n and n:1 references become relationships from that node
-
if a table has no primary key and two foreign-keys it becomes a relationship
-
tables and fields can be skipped
-
their names can be transformed (with a distinction between labels and relationship-types)
-
column values can be transformed as well (e.g. dates or decimals), null values are skipped
Implementing the tool was pretty straightforward, so everyone should be able to do something similar. Some details were a bit devilish, I’ll mention these in the appropriate places. The following sections explain some of the technical details, if you’re only interested in how to use the tool jump forward to the Example.
My first test was a simple Users being Friends database that I created in memory using Apache Derby, that went pretty well.
Looking for some MySQL demo databases, I found the Sakila artist database which could be imported out of the box but highlighted a concurrency issue - the parallel importer had to be started in a separate thread so that the reading from the relational database could progress in parallel.
And the much larger employees database. This one showed some peculiarities especially around composite primary and foreign keys. Especially foreign keys that are the same time part of the primary key are nasty. This forced me to extend the originally simple meta-data-model to cater for these cases.
But all prepared the tool really well for the final example.
Example
Of course the obligatory Northwind example couldn’t be left out. We also use it as an example for Cypher’s LOAD CSV statement and to compare Cypher with SQL. So I downloaded the import script from here and ran the it in my local MySQL server.
myql -u root < /path/to/Northwind.MySQL5.sql
I ran the import tool with these parameters: import-rdbms-mvn.sh "jdbc:mysql://localhost:3306/northwind?user=root" "northwind" "northwind.db"
It extracted the metadata, and the row-data from MySQL and imported it in into Neo4j. All in 3 seconds.
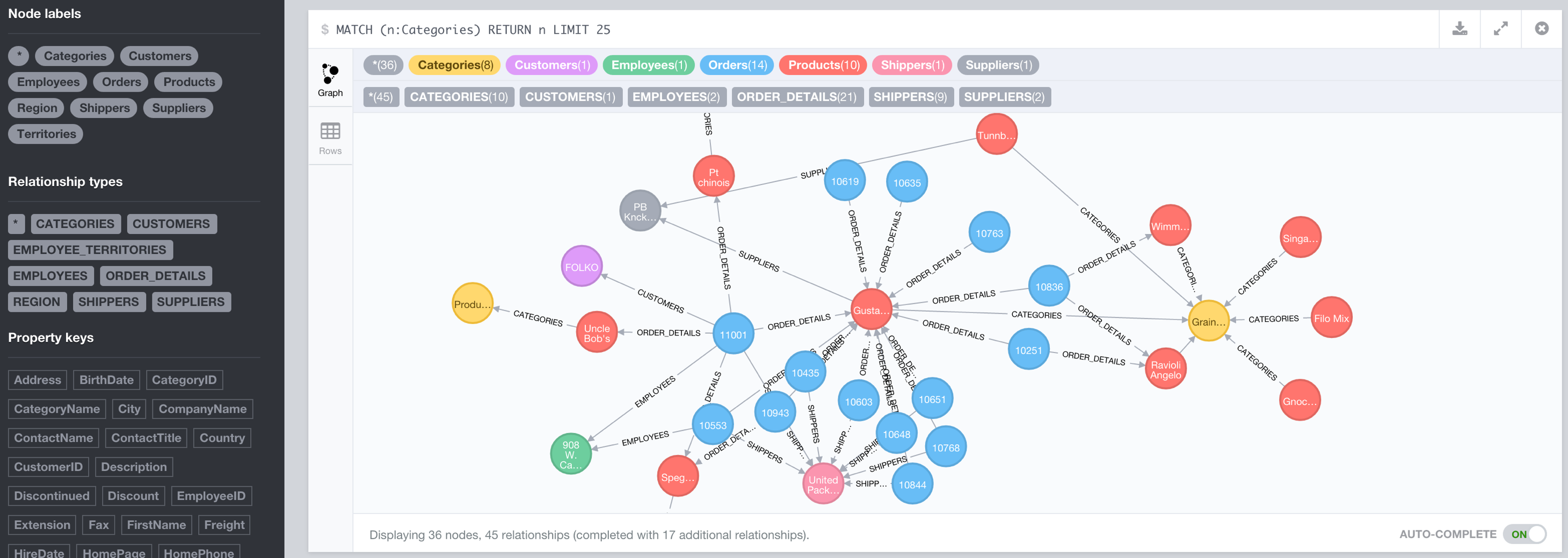
Looking at the meta-information in the Neo4j Browser shows that all expected labels and relationships are there.
It nicely imported the OrderDetails and EmployeeTerritories JOIN-tables as relationships.
As I was flying to London on Sunday I had enough time to finish the first iteration and write this blog post. So a weekend well spent.
Here you can find the tool: https://github.com/jexp/neo4j-rdbms-import
PLEASE test it out with your relational databases and send me feedback, best as GitHub Issues.
There are some more ideas, especially around parallelizing the reads from the relational database, configuring the mentioned rules and transformation and packaging it all up in to a nice little tool that can also be used by non-developers.