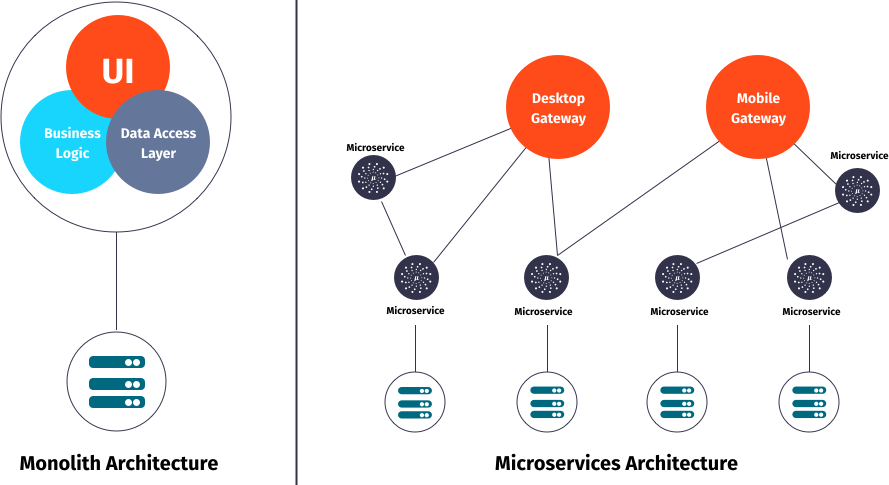
 JEXP
JEXP
JEXP
JEXPAufgrund der vielen coolen Features von Micronaut reichte ein Artikel einfach nicht aus, um das Framework hinreichend zu behandeln. Daher geht es heute weiter mit Themen wie Cloud-Deployment und Orchestrierung, Unterstützung für Serverless und Cloud-Functions, sowie der neuen Kafka Integration.
Seit dem letzten Heft gab es einige neue Micronaut-Releases, gerade eben ist Milestone 4 veröffentlich worden. Wenn dieser Artikel erscheint, halten wir ggf. schon das 1.0 Release in den Händen. Die Änderungen pro Release sind in der Dokumentation [MicroChanges] aufgeführt, ebenso die "breaking-changes" zwischen den Milestones.
Im letzten Artikel wurden einige Features schon behandelt, unter anderem
Http-Server und -Client
Jobs
Datenbankintegration
Unterstützung für Java, Kotlin, Groovy
Neue interessante Feature-Flags der letzten Milestones sind:
jrebel oder spring-loaded |
dynamisches Laden von geänderten Klassen während der Entwicklung |
cassandra |
Cassandra Unterstützung |
postgres-reactive |
reaktiver Treiber für Postgres |
jdbc-dbcp, jdbc-hikari, jdbc-tomcat |
JDBC Connection Pools |
kafka, kafka-streams |
Kafka Support |
management |
Management Endpunkt |
micrometer, micrometer-* |
Micrometer Unterstützung für diverse Reporter (Graphite, Prometheus etc.) |
picocli |
Kommandozeilenverarbeitung |
netflix-archius |
Netflix Archaius Konfigurationsmanagement |
Für neue Anwendungen und die Migration existierender Anwendungen zu einem Set von unabhängigen Diensten ist nicht nur Unterstützung des Entwicklungsprozesses wichtig, sondern auch Deployment und Operations besonders mit einem Fokus auf Cloud-Infrastruktur.
Durch die vielen verschiedenen Anbieter, Bibliotheken und Komponenten die im Cloud Umfeld um Aufmerksamkeit kämpfen, kann man schnell die Übersicht verlieren.
Prinzipiell sind allen "cloud-native" Anwendungen die meisten der folgenden Aspekte zu eigen:
Service Discovery / Orchestrierung
Konfiguration
Immutable Deployments
Effiziente Serviceinteraktion
Elastische Skalierung
Cloud-Awareness
Monitoring
Tracing
Security
Resilienz (auch Degrading)
Cloud-Functions
Micronaut unterstützt die meisten dieser Anforderungen schon von Hause aus. Dazu werden entsprechende Bibliotheken über "Features" integriert. Für spezielle Anwendungstypen (Service oder Funktion) und deren Zusammenfassung als "Federation" gibt es Profile, die die entsprechenden Code-, Konfigurations- und Abhängigkeitstemplates enthalten. Große Teile der ausführlichen Micronaut Dokumentation [MicroDoc] erklären die notwendigen Schritte, Features und Konfigurationen im Detail.
Die notwendigen Cloud Dienste (z.B. Consul oder Eureka) kann man lokal über Docker oder Kubernetes starten. Zum Teil stehen sie für Tests auch als eingebettete Bibliotheken zur Verfügung.
Da man in einer dynamischen Umgebung Abhängigkeiten zwischen Diensten nicht festzurren kann, wird auf eine Infrastruktur zur Auflösung von Namen zu Adressen und Konfigurationen aufgesetzt. Micronaut enthält Unterstützung für Consul, Eureka und Kubernetes, dafür gibt es auch ausführliche Anleitungen [Consul], [Eureka]. Für bestimmte Umgebungen kann die Namensauflösung auch fest auf eine Liste von Diensten konfiguriert werden.
Nachdem man den Namensservice als Feature aktiviert und konfiguriert hat, melden sich Micronaut Service-Instanzen automatisch beim Verzeichnisdienst an und ab.
Clients werden mittels Namensauflösung (Name in @Client Annotation) mit den Adressen von benötigten Diensten versorgt.
Hier ein Beispiel für Consul
Zuerst sollte man Consul z.B. mittels Docker starten. Es gibt eine UI auf http://localhost:8500/ui auf der man die angemeldeten Dienste sieht.
docker run -p 8500:8500 consul
micronaut:
application:
name: meetup-city
consul:
client:
registration:
enabled: true
defaultZone: "${CONSUL_HOST:localhost}:${CONSUL_PORT:8500}"
Dann können andere Services unseren Dienst nur über seinen Namen finden:
@Client(id = "meetup-city")
public interface CityClient {
//...
}Sofern Dienste auf mehr als eine Instanz skaliert wurden, nutzt die Micronaut Client Implementierung eine client-seitige "round-robin" Verteilung. Dienste können Anfragen auch an andere Instanzen weiterleiten sofern sie überlastet sind.
Es können aber auch spezifische Load-Balancer eingebunden werden, wie Netflix "Ribbon".
ribbon:
VipAddress: test
ServerListRefreshInterval: 2000Natürlich werden auch auf Cloud-Seite IP basierte Load Balancer wie HA-Proxy oder Elastic Load Balancer (ELB) unterstützt.
In verteilten Systemen treten Ausfälle kontinuierlich auf. Daher sollte schon bei der Entwicklung vorgesehen werden, dass abhängige Systeme mit entsprechenden Resilienz-Mustern [Friedrichsen] geschützt werden.
In Micronaut erfolgt das mit entsprechenden Annotationen (z.B. @Retryable und @CircuitBreaker) auf Client-Interfaces, die über AOP-Advices automatisch implementiert werden.
Das kann pro Methode oder für die ganze API (Interface oder Paket) erfolgen.
Alle Muster kommen mit sinnvollen Defaults, können aber beliebig konfiguriert werden.
@Retryable( attempts = "${retry.attempts:3}",
delay = "${retry.delay:1s}" )
@Client("city")
public interface CityClient { ... }Mit CircuitBreaker wird beim wiederholten (attempts) Fehler der Aufruf des fremden Dienstes für einen gewissen Zeitraum (reset) unterbunden und nach einer "Abkühlungszeit" wieder versucht.
Damit können sowohl kurzfristige Ausfälle als auch Überlastsituationen gehandhabt werden.
Für beide Muster können mit @Fallback annotierte Dienste vorgesehen werden, die sbei Ausfall eine lokale Implementierung bzw. Auditing umsetzen.
Wichtig ist, dass alle Resilienz-Integrationen ihren Status und Verlauf an eine Monitoringkomponente melden, so dass Zusammenhänge von Problemen festgestellt und Alarme bzw. Behebungsmassnahmen ausgelöst werden können.
Nutzer von Netflix' Hystrix Bibliothek können auch diese Resilienz-Lösung mit Micronaut integrieren, mit @HystrixCommand annotatierte Methoden werden dann von der Bibliothek gewrappt und als resiliente Kommandos ausgeführt.
Für das Monitoring von Diensten und Anwendungen stellt Micronaut verschiedene Arten von Endpunkten bereit. Jeder Endpunkt kann individuell konfiguriert und aktiviert werden.
|
Informationen über geladene Beans |
|
Statische Applikationsinformationen (aus Konfiguration und |
|
Verfügbarkeit der Anwendung (UP:HTTP-200, DOWN:HTTP-503 aggregiert aus |
|
Metriken (via Micrometer) |
|
Neuladen von Beans ( |
|
Routinginformationen |
|
Loggerinformationen & Loglevel |
Alle Management-Endpunkte integrieren automatisch mit den Security-Features von Micronaut.
Falls Informationen auch nicht-angemeldeten Nutzern gezeigt werden sollen, muss details-visible: ANONYMOUS gesetzt sein.
Für spezielle Anforderungen können auch eigenen Management-Endpunkte mittels @Endpoint annotierten Klassen bereitgestellt werden.
Seit Milestone 4 integriert Micronaut Monitoring mit [Micrometer] via das micrometer Features.
Sobald dieses aktiv ist, werden die in der MeterRegistry registrierten Meter vom /metrics Endpunkt zurückgegeben.
curl -s http://localhost:8080/metrics/system.cpu.usage | jq .
{
"name": "system.cpu.usage",
"measurements": [
{
"statistic": "VALUE",
"value": 0.27009646302250806
}
]
}
Micronaut stellt verschiedene Modifikatoren, Filter und Binder (Quellen wie JVM, System, Web-Requests, Logging) für Micrometer bereit. Natürlich können auch eigene Metriken integriert werden. Für das Reporting der Metriken zu den unterstützten Diensten (Graphite, Prometheus, Statsd, Atlas) gibt es noch einmal individuelle Konfigurationen.
curl -s http://localhost:8080/metrics/jvm.memory.max | jq .
{
"name": "jvm.memory.max",
"measurements": [
{
"statistic": "VALUE",
"value": 5609357311
}
],
"availableTags": [
{
"tag": "area",
"values": [
"heap",
"nonheap"
]
},
{
"tag": "id",
"values": [
"Compressed Class Space",
"PS Survivor Space",
"PS Old Gen",
"Metaspace",
"PS Eden Space",
"Code Cache"
]
}
]
}
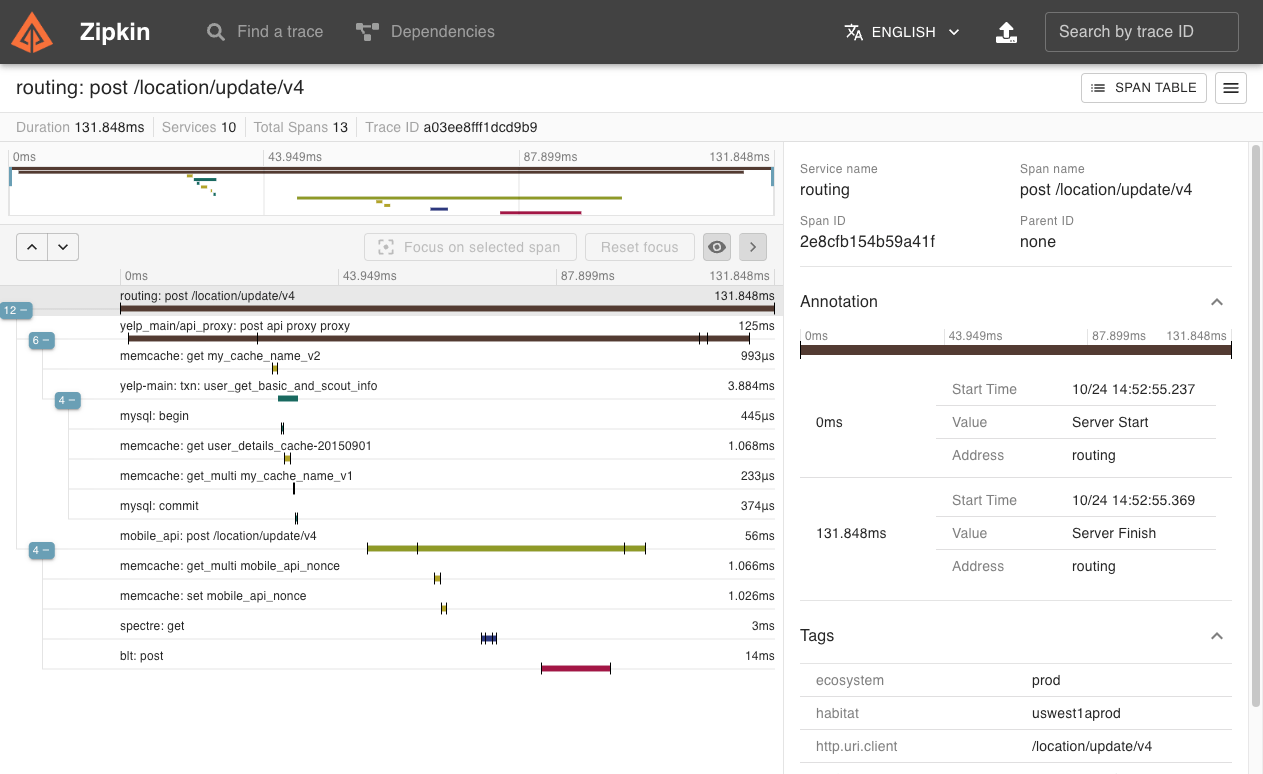
Besonders in verteilten Architekturen ist es wichtig, Anfragen über Dienstgrenzen hinweg zu verfolgen. Dazu kann die [OpenTracing] API mittels der Integration von "Zipkin" (von Twitter) bzw. "Jaeger" (von Uber) genutzt werden.
Nach Aktivierung des Features werden benannte Request- und andere Laufzeit-Informationen ("spans") erzeugt aber nur Bruchteile (z.b. 0.1% davon) den jeweiligen Dienst übermittelt. Diese Tools können daraus einen Laufzeitgraphen erzeugen und aggregierte Latenz-, Abhängigkeits-, und Fehlerreports visualiseren.
Micronaut stellt mittels verschiedener Mechanismen (z.B. Instrumentation, Http-Header) sicher dass die relevanten Informationen über Thread- und Service-Grenzen hinweg propagiert werden.
Die Namensinformation und Payload-Informationen für die Tracing-API kommen aus Annotationen auf Service-Methoden.
Mittels @NewSpan("name") wird ein neuer Trace gestartet, der dann auf Methoden mit @ContinueSpan fortgesetzt wird.
Parameter annotiert mit @SpanTag("tag.name") werden dem Trace hinzugefügt.
@Singleton
@Controller
class RecommendationController {
@NewSpan("event-recommendation")
@Get("/recommend")
public Event recommend(@SpanTag("user.id") String id) {
return computeRecommendation(userService.loadUser(id));
}
@ContinueSpan
public Event computeRecommendation(User user) {
return eventService.recommend(user, 1);
}
}Die jeweiligen Clients können natürlich noch individuell konfiguriert werden, es gibt auch die Möglichkeit, eigene Tracer einzubinden.
Da Microservice Anwendungen aus mehreren, überschaubaren Diensten bestehen, die miteinander kommunizieren, ist es sinnvoll sie in getrennten Modulen zu verwalten. Viele der Infrastrukturdienste (Orchestrierung, Monitoring, Resilienz, Eventprotokoll) sind aber in jedem der Teilprojekte notwendig. Andere Features wie Datenbankanbindung, oder Machine-Learning Bibliotheken sind pro Projekt verschieden.
Mit dem "Federation" Profil kann so ein Gesamtprojekt generiert werden, dass die Teilprojekte mit erzeugt und konfiguriert, aber auch eine Build-Konfiguration für das Gesamtprojekt bereitstellt.
mn create-federation meetup --services users,groups,events,locations,recommendation --feature config-consul,discovery-consul,http-client,http-server,security-jwt,... --profile service --build gradle
Mit Micronaut’s "function" bzw. "function-aws" Profilen, ist es einfach einzelne Funktionen für "serverless" Infrastruktur zu entwickeln und deployen.
Mittels mn create-function erzeugt man diese statt einer Anwendung.
In Groovy werden einfach Top-Level Funktionen und in Java/Kotlin Beans mit annotierten Methoden genutzt, dort werden auch die funktionalen Interfaces aus java.util.function.* implementiert.
mn create-function recommend
@FunctionBean("recommend")
public class RecommendFunction implements Function<User, Single<Event>> {
@Inject RecommendationService service;
@Override
public Single<Event> recommend(User user) {
return service.recommend(user).singleOrError();
}
}Wie auch Services, melden sich Funktionen beim ggf. konfigurierten Service Discovery Dienst an.
Konsumiert werden Funktionen über einen speziellen Client, der ähnlich wie der HttpClient funktioniert, nur mit @FunctionClient("name") annotiert ist.
Jede Methode des Client-Interfaces repräsentiert eine Funktion, die natürlich auch wieder reaktive Typen als Ergebnisse benutzen kann.
Die generierte Implementierung des Clients kümmert sich dann z.B. mittels Service Discovery um den Lookup der Funktion und die nachfolgende Ausführung.
@FunctionClient("meetup")
static interface MeetupClient {
Single<Event> recommend(User user);
@Named("rating")
int stars(Group group);
}
Um Funktionen zu testen, kann man diese direkt im Test aufrufen, oder auch mittels des function-web Features im HTTP-Server laufen lassen.
Dann sind sie entweder als GET oder POST Operation verfügbar, je nachdem ob sie Parameter entgegennehmen oder nicht.
curl -X POST -d'{"userId":12345}' http://localhost:8080/recommend
@Test
void testStars() {
EmbeddedServer server = ApplicationContext.run(EmbeddedServer.class)
MeetupClient client = server.getApplicationContext().getBean(MeetupClient.class)
assertEquals(4, client.stars(new Group("4-Stars")))
}
Funktionen können auch als CLI-Anwendungen ausgeführt werden.
Das ausgeführte Fat-Jar nimmt Parameter über std-in entgegen und gibt Ergebnisse über std-out zurück.
AWS Lambda Funktionen können im "function-aws" Profil mit zusätzlich aktivierten Gradle Plugins direkt nach AWS deployed und dort aufgerufen werden, sofern AWS Zugangsdaten verfügbar sind.
Diese Funktionen können dann für den FunctionClient in der application.yml bekannt gemacht werden.
aws:
lambda:
functions:
recommend:
functionName: recommendEvent
region: us-east-1
Mittels Docker wird auch "OpenFaaS" Deployment unterstützt, dazu muss nur das "openfaas" Feature aktiviert werden. Hier wird die Ausführung von Funktionen als Kommandozeilenanwendung genutzt.
Standardmässig generiert Micronaut ein Dockerfile für jedes Projekt, das direkt im Build-Prozess genutzt werden kann und auch für "immutable deployments" geeignet ist.
Es basiert auf dem Alpine-Image und inkludiert das Fat-JAR aus dem Buildprozess dass dann über java -jar gestartet wird.s
mn create-app micronaut-docker-beispiel
FROM openjdk:8u171-alpine3.7
RUN apk --no-cache add curl
COPY target/micronaut-example*.jar micronaut-docker-beispiel.jar
CMD java ${JAVA_OPTS} -jar micronaut-docker-beispiel.jar
./gradlew shadowJar docker build . docker run cd21fba541e5 -p 8080:8080 01:31:04.314 [main] INFO io.micronaut.runtime.Micronaut - Startup completed in 1231ms. Server Running: http://localhost:8080
Micronaut kann auf die Google Cloud über ein Fat-JAR, dass die Anwendung mit dem notwendigem Server und Bibliotheken enthält mit den gcloud Kommandozeilentools deployed werden.
Im [GCPGuide] werden die einzelnen Schritte erläutert, prinzipiell lädt man das JAR in einen Bucket und schreibt dann ein Start-Script für die Instanz, das das Jar lädt, Java installiert und es mittels java -jar startet.
Dieses Script wird von gcloud compute instances create benutzt, danach wird für Port 8080 eine Firewall-Regel angelegt und nach ein paar Minuten ist der Dienstes gestartet und steht zur Verfügung.
Mittels eines Gradle Plugins können Lambda Funktionen direkt aus dem Build-Prozess deployed und aufgerufen werden, sofern man valide AWS Zugangsdaten in .aws/credentials vorliegen hat.
if(new File("${System.getProperty("user.home")}/.aws/credentials").exists()) {
task deploy(type: jp.classmethod.aws.gradle.lambda.AWSLambdaMigrateFunctionTask, dependsOn: shadowJar) {
functionName = "echo"
handler = "io.micronaut.function.aws.MicronautRequestStreamHandler"
role = "arn:aws:iam::${aws.accountId}:role/lambda_basic_execution"
runtime = com.amazonaws.services.lambda.model.Runtime.Java8
zipFile = shadowJar.archivePath
memorySize = 256
timeout = 60
}
task invoke(type: jp.classmethod.aws.gradle.lambda.AWSLambdaInvokeTask) {
functionName = "echo"
invocationType = com.amazonaws.services.lambda.model.InvocationType.RequestResponse
payload = '"foo"'
doLast {
println "Lambda function result: " + new String(invokeResult.payload.array(), "UTF-8")
}
}
}
BUILD SUCCESSFUL in 1m 48s 4 actionable tasks: 3 executed, 1 up-to-date
> Task :invoke Lambda function result: "foo" "foo"
In Microservices-Architekturen setzten sich eventbasierte Integrationsschichten immer mehr durch. Obwohl Micronaut mit den reaktiven Http-Servern in Bezug auf Flow-Control schon mithalten konnte, sind andere Aspekte verteilter, persistenter Event-Logs natürlich sehr vorteilhaft. Daher wurde im Milestone 4 Unterstützung für Apache Kafka bereitgestellt.
Dazu gibt es auch ein neues Profil für reine Kafka-Services, ohne HTTP-Server.
Aber auch andere Dienste und Funktionen können mittels Feature-Flag Unterstützung für Kafka bzw. Kafka-Streams erhalten.
Die ggf. aktivierte Micrometer-Registry enthält dann auch die Kafka-Metriken, und der /health Endpunkt gibt Auskunft über den Zustand der Verbindung.
mn create-app rsvp-loader --profile kafka
Dieser Dienst kommuniziert wie konfiguriert mit Kafka über localhost:9092.
Ein oder mehrere Kafka-Server können in der Anwendungskonfiguration, aber auch über KAFKA_BOOTSTRAP_SERVERS gesetzt werden.
kafka:
bootstrap:
servers: localhost:9092
Zum Testen kann man entweder EmbeddedKafka (mittels kafka.embedded.enabled) benutzen, oder Kafka mittels Docker [KafkaDocker] starten.
Micronaut Services und Funktionen können deklarativ mittels Annotationen als Konsumenten und Publisher von Events auf Topics definiert werden.
Etwas verwirrend benannt, ist ein mit @KafkaClient annotiertes Bean eine Quelle von Events.
mn create-kafka-producer Rsvp | Rendered template Producer.java to destination src/main/java/rsvp/loader/RsvpProducer.java
@KafkaClient
public interface RsvpProducer {
@Topic("rsvps")
void sendRsvp(@KafkaKey String id, Rsvp rsvp);
}Wie gehabt, wird die Implementierung des Interfaces von Micronaut vorgenommen.
Neben dem Payload können auch noch weitere, annotierte Parameter übergeben werden, wie Partition oder Header.
Auch hier können reaktiven Typen wie Flowable oder Single`für Payload und Ergebnisse genutzt werden, so dass man auch auf die Ergebnisse der Publikation abonnieren kann.
Man kann auch ein Kafka - `RecordMetadata zurückgeben, das enthält dann alle Detailinformationen des Sendevorgangs.
Batching wird mit @KafkaClient(batch=true) aktiviert, dann werden Listen von mehreren Entitäten als Batch behandelt und nicht als einzelner, grosser Payload serialisiert.
@KafkaClient(batch=true)
public interface RsvpBatchProducer {
@Topic("rsvps")
Flowable<RecordMetadata> sendRsvp(@KafkaKey Flowable<String> ids, Flowable<Rsvp> rsvps);
}Benutzt wird der Produzent wie folgt:
@Inject RsvpProducer producer;
// oder
RsvpProducer producer = applicationContext.getBean(RsvpProducer.class);
producer.sendRsvp("293y89dcd", new Rsvp(....));Für produktive Deployments von Kafka wird eine Vielzahl von Konfigurationsoptionen in @KafkaClient("producer-id") unterstützt - Serialisierung, Retries, Acknowledgement, usw.
Standardmässig werden Jackson-Serializer für JSON genutzt, diese sind aber entweder global oder pro Producer/Consumer konfigurierbar.
Für sehr spezielle Anwendungsfälle kann man sich auch direkt KafkaProducer der Kafka-API injizieren lassen und hat dann die volle Flexibilität.
Mittels @KafkaListener werden Nachrichten von einem oder mehreren Topics abonniert.
mn create-kafka-listener Rsvp | Rendered template Listener.java to destination src/main/java/rsvp/loader/RsvpListener.java
@KafkaListener(offsetReset = OffsetReset.EARLIEST)
public class RsvpListener {
@Inject RsvpRepository repo;
@Topic("rsvps")
public void receiveRsvp(@KafkaKey String id, Rsvp rsvp) {
repo.storeRsvps(Flowable.fromArray(rsvp));
}
}
Auch hier können eine Menge zusätzlicher Parameter angegeben werden, wie Offset, Partition, Zeitstempel, Topic, Header, oder halt gleich ein Kafka ConsumerRecord.
Für Batchverarbeitung kann auch hier @KafkaListener(batch=true) genutzt werden und dann entweder Listen oder reaktive Streams von Parametern verarbeitet werden.
@KafkaListener(batch=true, offsetReset = OffsetReset.EARLIEST)
public class RsvpBatchListener {
@Inject RsvpRepository repo;
@Topic("rsvps")
public void receiveRsvp(@KafkaKey Flowable<String> ids, Flowable<Rsvp> rsvps) {
repo.storeRsvps(rsvps);
}
}
Praktischerweise kann mittels @SendTo("topic",…) Annotation das Ergebnis des Methodenaufrufs an einen weiteren Topic weitergeleitet werden.
Es gibt noch weitere Konfigurationen für Thread-Management, Timeouts, Serialisierung für einzelne Consumer oder Gruppen, die in der Dokumentation im Detail erläutert werden. Offset Commit-Management ist ein eigenes Thema für sich, das auch Fehlerbehandlung, asynchrone Verarbeitung, Bestätigungsmanagement, Offset-Recovery und Re-Delivery Bezug nimmt.
Streaming Data (Fast Data) Architekturen (Akka, Kafka, Flink, Spark) werden immer verbreiteter. Dabei läuft der eigene Code als Prozessoren auf dem Stream, die Daten aggregieren, filtern oder neue Streams erzeugen können. Micronaut’s schlanke Runtime sollte für solche Verarbeitung entsprechend wenig Overhead verursachen.
Für Kafka-Streams ist nem den Bibliotheken und der Kafka-Konfiguration eine @Factory notwendig, deren "process" Methode, einen ConfiguredStreamBuilder entgegennimmt und einen typisierten KStream der Kafka-Streams API zurückgibt.
Hier ist ein minimales Beispiel, ohne den Konfigurationscode für Serialisierung.
@Factory
public class NoRsvpFilterStream {
public static final String INPUT = "streams-plaintext-input";
public static final String OUTPUT = "streams-wordcount-output";
@Singleton
KStream<String, Rsvp> yesRsvpFilter(ConfiguredStreamBuilder builder) {
// Serializer Konfiguration ...
KStream<Rsvp, Rsvp> source = builder.stream("rsvps");
return source
.filter( rsvp -> rsvp.yes ).to("yes-rsvps");
}
}
Die Topics dieser Streams können dann ganz regulär von "Upstream"-Produzenten mit Daten versorgt und ihre Ergebnisse von Downstream-Konsumenten verarbeitet werden.
Zusammen mit der Neuentwicklung des mn Tools mittels picocli gibt es jetzt sowohl ein cli Profil für reine Kommandozeilenanwendungen.
Man kann mittels create-cli-app so eine Anwendung erzeugen und dann in dieser mittels create-command weitere Kommandos anlegen.
Mehr Informationen zur API gibt es bei PicoCLI
mn create-cli-app list
Das Kommando sieht dann (angepasst) so aus:
@Command(name = "list", description = "Listing of entities",
mixinStandardHelpOptions = true)
public class ListCommand implements Runnable {
@Option(names = {"-c", "--cities"}, description = "list cities")
boolean listCities;
@Inject CityClient cities;
public static void main(String[] args) throws Exception {
PicocliRunner.run(ListCommand.class, args);
}
public void run() {
if (listCities) {
cities.list().map(c -> c.name).forEach(System.out::println);
}
}
}
Neben gradlew run kann man mit gradlew assemble die Kommandozeilen Anwendung auch in eine Zip distribution packen, die dann alle Abhängigkeiten und Shell-Skripte für OSX, Unix und Windows enthält.
Die können wir dann mit bin/list -c ausführen.
Es wäre schön in der Zukunft für diese vielleichte eine Graal-VM Variante, oder ein auf der Shell ausführbares Jar wie bei Spring-Boot zu unterstützen.
Mit create-cli-app kann man Kommandozeilenanwendungen erzeugen, die Dienste wie reguläre Konsumenten oder Produzenten benutzen
@Singleton Beans können mit @Parallel annotiert werden, um parallele Initialisierung zu ermöglichen.
Lombok’s Annotation Prozessor sollte vor Micronaut laufen.
JDBC Connections können jetzt den Spring-JDBC Transaction Manager nutzen
Es werden JDBC Connection Pools unterstützt
spring-loaded oder jrebel helfen bei dem dynamischen Neuladen von Klassen
Eine neue AOP-Advice "Method-Adapter" mit der Meta-Annotation @Adapter, erlaubt es annotierte Methoden, als Single-Abstract-Method (SAM) Beans bereitzustellen, die ein bestimmtes Interface implementieren.
Das wird z.B. für die @EventListener Annotation genutzt, die Methoden für die Verarbeitung Application-Events markiert.
Eigentlich ist Micronaut ja kein klassisches Web-Framework, um HTML und andere Inhalte zu rendern.
Seit neuestem werden aber mittels des io.micronaut:views Moduls, und die jeweiligen Bibliotheken der Template-Engines wie Thymeleaf, Velocity und Handlebars unterstützt.
Die Template Dateien liegen in src/main/resource/views und Controllermethoden die mit @View("name") annotiert sind sowie Maps, POJOs bzw. ModelAndView zurückgeben, stellen die Render-Informationen bereit.
Die @Requires Annotation für das dynamische Aktivieren von Beans abhänging von externen Bedingungen ist extrem flexibel, hier sind ein paar Beispiele
@Requires(beans = DataSource.class)
@Requires(property = "enabled")
@Requires(missingBeans = EmployeeService)
@Requires(sdk = Sdk.JAVA, value = "1.8")
Mit Micronaut ist man bestens gewappnet, auch komplexe service-basierte Systeme zu entwickeln, integrieren, deployen, robust laufen zu lassen und zu überwachen. Dank der Aktualität des Frameworks sind moderne Tools für diese Aufgaben schon integriert. Für die Nutzung der verschiedenen Cloud-Provider, zB. für Cloud-Functions ist noch einiges zu tun, zur Zeit wird nur AWS automatisch unterstützt. Dank der Kafka Integration hat man die Wahl für die Inter-Service-Kommunikation HTTP- oder ereignisbasierte Protokolle zu nutzen.
Micronaut kann aber nicht nur für klassische Backend-Dienste genutzt werden. OCI Entwickler Ryan Vanderwerf zeigt im [GalecinoCar] Projekt wie Micronaut zusammen mit ML-Frameworks und Robo4j ein selbstfahrendes Modellauto auf einem Raspberry PI steuert.
Ich freue mich schon auf die weitere Entwicklung des Frameworks. Bisher sind die durchdachten Features, Hilfe und Aktivität in der Community und die schnellen Bugfixes sehr beeindruckend.
Ich vermisse eigentlich nur die Möglichkeit, "Features" in existierenden Projekten mittels mn --feature zu aktivieren, und so konsistent und korrekt neue Abhängigkeiten und Konfigurationen hinzuzufügen.
[MicroDoc] https://docs.micronaut.io/
[MicroChanges] https://docs.micronaut.io/latest/guide/index.html#whatsNew
[MicroIntro] https://objectcomputing.com/resources/publications/sett/july-2018-micronaut-framework-for-the-future
[MicroGuides] http://guides.micronaut.io u.a. für Consul, Eureka, Zipkin, Jaeger
[GuideConsul] http://guides.micronaut.io/micronaut-microservices-services-discover-consul/guide/index.html
[GuideEureka] http://guides.micronaut.io/micronaut-microservices-services-discover-eureka/guide/index.html
[GuideZipkin] http://guides.micronaut.io/micronaut-microservices-distributed-tracing-zipkin/guide/index.html
[GuideJaeger] http://guides.micronaut.io/micronaut-microservices-distributed-tracing-jaeger/guide/index.html
[MicroWorkshop] https://alvarosanchez.github.io/micronaut-workshop/
[GalecinoCar] https://objectcomputing.com/resources/events/webinars/galecino-car/recording
[Friedrichsen] http://www.informatik-aktuell.de/entwicklung/methoden/resilient-software-design-robuste-software-entwickeln.html
[OpenTracing] http://opentracing.io
[OpenFaaS] https://www.openfaas.com/
[KafkaDocker] https://docs.confluent.io/current/installation/docker/docs/configuration.html
[Baeldung] http://www.baeldung.com/micronaut